Focal Loss 详解:图示 + 数学原理 + 代码
本文内容
简介
论文:Focal Loss for Dense Object Detection (2017.08,Meta)
Focal Loss 通常应用于目标检测的类别,它是对交叉熵损失函数(参考 交叉熵损失函数(Cross Entropy Loss):图示+公式+代码 )的改进。
在目标检测的训练过程中,目标类别与背景图类别之间的数量极不平衡。Focal Loss 通过重塑标准交叉熵损失来解决这种类别不平衡问题,对分类良好的样本的损失进行降权,从而将训练集中在稀少的硬样本(hard examples)上,防止在训练过程中大量容易分类的负样本影响训练过程。
公式
假如模型的预测值(已经 sigmod)为 ,定义 如下,
损失函数(Focal Loss)定义如下
其中
- (代码中参数 gamma)论文中取 2 时效果最好,YOLOv8 的代码中默认取 1.5。
- YOLOv8 的代码中,(代码中参数 alpha)在正样本取 0.25,负样本取 0.75。
取不同值时的损失函数图像如下。
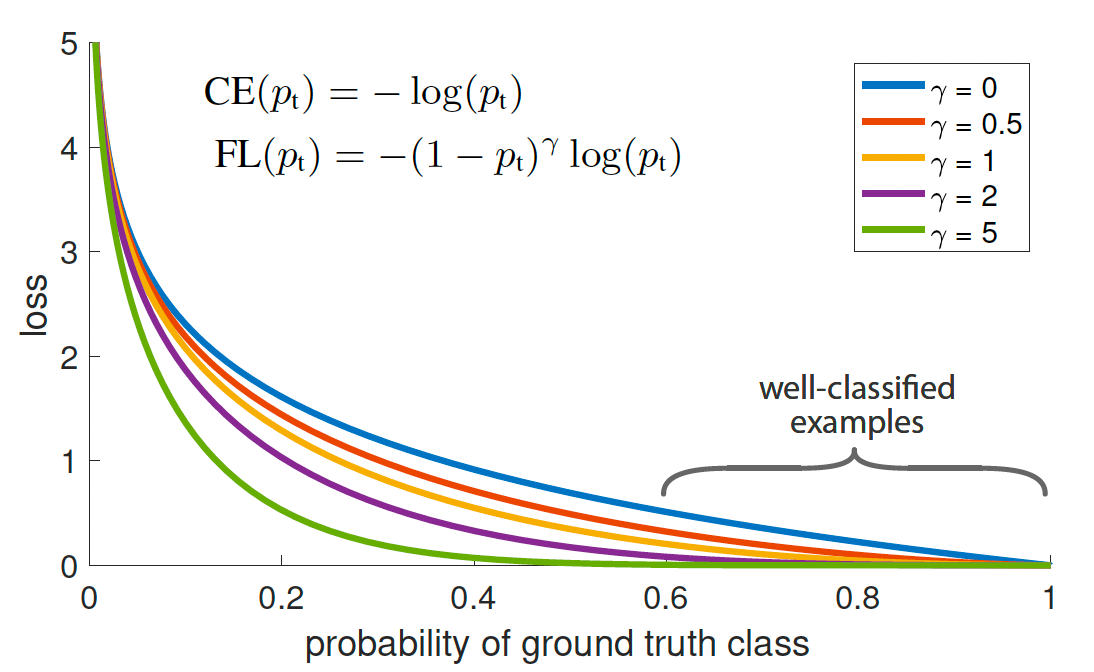 图 1:Focal Loss 降低了容易分类()的样本的损失, 将更多注意力放在难的、被错误分类的样本上。
图 1:Focal Loss 降低了容易分类()的样本的损失, 将更多注意力放在难的、被错误分类的样本上。
在后面的例子中,我们假定 的样本中,有两个预测值分别为(0.8, 0.4)。显然,0.8 很容易分类,0.4 很难分类。可以看出,Focal Loss 降低了容易分类()的样本的损失占比, 将更多注意力放在难的、被错误分类的样本上()。两个值的损失值差异从约 4 倍提升到了约 37 倍(注意,损失的绝对值两者都是降低的,但是训练比较的是相对值)。
| 预测值 | CE 损失(Cross Entropy Loss) | Focal Loss () |
|---|---|---|
| 0.8 | 0.2231 | 0.0089 |
| 0.4 | 0.9163 | 0.3299 |
| 两者对比 | 4.11 | 36.96 |
YOLOv8 中的代码实现
# 参考 ultralytics/ultralytics/utils/loss.py
import torch.nn as nn
import torch.nn.functional as F
class FocalLoss(nn.Module):
"""Wraps focal loss around existing loss_fcn(), i.e. criteria = FocalLoss(nn.BCEWithLogitsLoss(), gamma=1.5)."""
def __init__(self, ):
"""Initializer for FocalLoss class with no parameters."""
super().__init__()
@staticmethod
def forward(pred, label, gamma=1.5, alpha=0.25):
"""Calculates and updates confusion matrix for object detection/classification tasks."""
loss = F.binary_cross_entropy_with_logits(pred, label, reduction='none')
# p_t = torch.exp(-loss)
# loss *= self.alpha * (1.000001 - p_t) ** self.gamma # non-zero power for gradient stability
# TF implementation https://github.com/tensorflow/addons/blob/v0.7.1/tensorflow_addons/losses/focal_loss.py
pred_prob = pred.sigmoid() # prob from logits
p_t = label * pred_prob + (1 - label) * (1 - pred_prob)
modulating_factor = (1.0 - p_t) ** gamma
loss *= modulating_factor
if alpha > 0:
alpha_factor = label * alpha + (1 - label) * (1 - alpha)
loss *= alpha_factor
return loss.mean(1).sum()
举例看看具体计算过程
import torch
import math
#--------------- 直接算 Cross Entropy Loss 和 Focal Loss,便于和后面类库计算的对照看 ---------------
# 假定有两个目标值都为 1 的预测值(即 p),其中一个为 0.8,另一个为 0.4
# 交叉熵的计算公式为:-log(预测值)
ce08 = -math.log(0.8) # 预测值 0.8 的交叉熵
ce04 = -math.log(0.4) # 预测值 0.4 的交叉熵
# 指定精度为 4 位小数
print(f"交叉熵损失(分别为 0.8 的 CE,0.4 的 CE,比率):{ce08:.4f} {ce04:.4f} {ce04/ce08:.2f}") # 输出:
# 输出:交叉熵损失(分别为 0.8 的 CE,0.4 的 CE,比率):0.2231 0.9163 4.11
gamma=2
fl08 = -(1-0.8)**gamma * math.log(0.8) # 预测值 0.8 的 focal loss
fl02 = -(1-0.4)**gamma * math.log(0.4) # 预测值 0.4 的 focal loss
print(f"Focal Loss(分别为 0.8 的 FL,0.4 的 FL,比率):{fl08:.4f} {fl02:.4f} {fl02/fl08:.2f}")
# 输出:Focal Loss(分别为 0.8 的 FL,0.4 的 FL,比率):0.0089 0.3299 36.96
#【可以看出,0.4 这个样本在 FL 中的权重明显增大】
#--------------- 使用 PyTorch 库和 YOLOv8 的库计算 Cross Entropy Loss 和 Focal Loss ---------------
loss = torch.nn.CrossEntropyLoss(reduction='none')
# nn.CrossEntropyLoss会对输入值做softmax(做exp),故这里为了方便说明,指定exp后的值
input = torch.tensor([[math.log(0.2), math.log(0.8)]], requires_grad=True)
target = torch.tensor([1]) # 目标值为 1
output = loss(input, target)
output.backward()
print("预测值 0.8 的 CE:", output)
# 输出:预测值 0.8 的 CE: tensor([0.2231], grad_fn=<NllLossBackward0>)
input = torch.tensor([[math.log(0.6), math.log(0.4)]], requires_grad=True)
output = loss(input, target)
output.backward()
print("预测值 0.4 的 CE:",output)
# 输出:预测值 0.4 的 CE: tensor([0.9163], grad_fn=<NllLossBackward0>)
# 类库FocalLoss计算时,会做一次 sigmod,这里为方便说明,取 sigmod 的逆运算
logit08 = -math.log((1/0.8) - 1)
# p=0.8对应的 Odds 值为4(0.8/(1-0.8),取对数即为logit 值,详细请参考 https://www.vectorexplore.com/tech/term/logit.html
# 这种计算出的结果和上面的逆运算等价。torch.nn.functional.binary_cross_entropy_with_logits 的输入要求是 logit 值。
logit08 = math.log(0.8/0.2)
logit04 = -math.log((1/0.4) - 1)
# 或者 直接写 logit 值
logit04 = math.log(0.4/0.6)
from focal_loss import FocalLoss
focalLoss = FocalLoss()
pred = torch.tensor([[logit08]], requires_grad=False)
label = torch.tensor([[1.0]], requires_grad=False)
loss = focalLoss.forward(pred, label, gamma=gamma, alpha=1) # 注意参数和上面的保持一致。
print("YOLOv8 类库计算的预测值 0.8 的 FL:", loss)
# 输出: YOLOv8 类库计算的预测值 0.8 的 FL: tensor(0.0089)
pred = torch.tensor([[logit04]], requires_grad=False)
loss = focalLoss.forward(pred, label, gamma=gamma, alpha=1) # 注意参数和上面的保持一致。
print("YOLOv8 类库计算的预测值 0.4 的 FL:", loss)
# 输出:YOLOv8 类库计算的预测值 0.4 的 FL: tensor(0.3299)
发布于:2023-11-21 最后更新:2024-05-31 描述有误?我来纠错