本文介绍当前目标检测技术相关的类库和论文,欢迎大家补充。
本文内容
- 目标检测工具箱(object detection toolbox)
- 基础性论文
- Backbone
- 视觉模型架构的一些基础方法
- 目标检测模型架构
- 损失函数
- 其他重要论文
- 训练方法
目标检测工具箱(object detection toolbox)
ultralytics(YOLOv8 和 YOLOv5、YOLOv9等)
Ultralytics 库以 YOLOv8 起家,目前包含了YOLOv3~YOLOv9、RT-DETR、FastSAM 等模型。
无论文发表。AGPL-3.0 协议,商用需付费。
- YOLOv8
- GitHub:YOLOv8
:Real-Time Object Detection with YOLOv8
- 功能:
- 目标检测和跟踪、物体分割、图像分类、姿态预估。
- 和各个 AI 平台的集成:数据标注(Roboflow)、模型训练过程管理(ClearML,Comet)、模型部署和推理(Neural Magic,OpenVINO)
- GitHub:YOLOv8
- YOLOv5

mmdetection(open-mmlab)
论文:MMDetection: Open MMLab Detection Toolbox and Benchmark (2019.06,OpenMMLab)
代码:open-mmlab/mmdetection

Detectron2(Facebook)
Detectron2 
Tensorflow Detection API
PaddleDetection(百度)
PaddleDetection 
基础性论文
CNN(AlexNet)
大规模深度卷积神经网络的开山之作。
- 论文:ImageNet classification with deep convolutional neural networks
(2012.12,多伦多大学(Alex Krizhevsky, Ilya Sutskever, Geoffrey E. Hinton))
Transformer(2017.06,Google)
- 论文:Attention Is All You Need
(2017.06,Google)
- 参考 深度学习 Transformer 架构详解:代码 + 图示
Backbone
ResNet
- 论文:Deep Residual Learning for Image Recognition
(2015.12,何恺明(微软))
- 亮点:残差训练,解决网络深度难训练的问题。
Swin Transformer (2021.03, Microsoft)
- 论文:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
(2021.03,微软)
代码:microsoft/Swin-Transformer - 亮点:层次(hierarchical Transformer)、移动窗口(shifted window)

Vision Transformer (ViT) (2020.10, Google)
- 论文:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
(2020.10,Google)
- 亮点:将 Transformer 应用到图像上(目前火爆的 Sora 也基于此技术)。
视觉模型架构的一些基础方法
FPN(2016.12,Meta 等)
- 论文:Feature Pyramid Networks for Object Detection
(2016.12,Meta 等)
- 亮点:特征金字塔。Top-down pathway,即将上层特征(深层网络,空间感较弱,但语义较强的特征)融合到浅层网络特征(空间感较强,但语义较少的特征)中。
另外,可以参考 PANet 网络骨架(参考)
SPP(空间金字塔池化)(2014.06,何恺明等)
- 论文:Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition
(2014.06,何恺明)
- 亮点:Spatial Pyramid Pooling(空间金字塔池化)通过在特征图上执行不同大小的池化操作,并将结果进行整合,从而得到固定尺寸的输出。这种技术可以有效地处理尺寸变化多样的目标,从而提高了神经网络的泛化能力和鲁棒性。
目标检测模型架构
YOLO 系列
实时检测用。有兴趣的,可以参考以下论文和代码库。
- YOLOv10
- 论文:YOLOv10: Real-Time End-to-End Object Detection
(2024.05,清华大学)
代码:THU-MIG/yolov10
- 论文:YOLOv10: Real-Time End-to-End Object Detection
- YOLOv9
- 论文:YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
(2024.04,台湾省“中研院”等)
代码:WongKinYiu/yolov9
- 论文:YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information
- YOLOv7
- 论文:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
(2022.07,台湾省“中研院”等)
代码:WongKinYiu/yolov7
- 论文:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
- YOLOv6
- 论文:YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
(2022.09,美团)
代码:meituan/YOLOv6 - 更新版:YOLOv6 v3.0: A Full-Scale Reloading
(2023.01,美团)
- 论文:YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications
- YOLOX
- 论文:YOLOX: Exceeding YOLO Series in 2021
(2021.07,旷视)
- 论文:YOLOX: Exceeding YOLO Series in 2021
- YOLOF
- 论文:You Only Look One-level Feature
(2021.03,中国科学院,旷视等)
- 论文:You Only Look One-level Feature
- YOLOv4
- 论文:YOLOv4: Optimal Speed and Accuracy of Object Detection
(2020.04,AlexeyAB、台湾省“中研院”)
代码:AlexeyAB/darknet
- 论文:YOLOv4: Optimal Speed and Accuracy of Object Detection
- YOLOv3
- 论文:YOLOv3: An Incremental Improvement
(2018.04,华盛顿大学)
- 亮点:残差,借鉴特征金字塔的思想
- 论文:YOLOv3: An Incremental Improvement
- YOLOv2
- 论文:YOLO9000: Better, Faster, Stronger
(2016.12,华盛顿大学)
- 论文:YOLO9000: Better, Faster, Stronger
- YOLOv1
- 论文:You Only Look Once: Unified, Real-Time Object Detection
(2015.06,华盛顿大学)
- 亮点:YOLO 和 R-CNN 系列模型不同,YOLO 将目标检测视为一个单一的回归问题,它直接根据图像像素(注:回归),同时(注:Only Look Once)预测边界框的坐标和各个类别的概率。
- 论文:You Only Look Once: Unified, Real-Time Object Detection





R-CNN 系列
Cascade Mask R-CNN (2019.06, UC San Diego)
前一篇 Cascade R-CNN 论文(见后)的更新版本。
- 论文:Cascade R-CNN: High Quality Object Detection and Instance Segmentation
(2019.06,UC San Diego)
Cascade R-CNN (2017.12, UC San Diego)
- 论文:Cascade R-CNN: Delving Into High Quality Object Detection
(2017.12,UC San Diego)
- 亮点:一系列 IoU 阈值递增的检测器
Mask R-CNN (2017.03, Meta)
- 论文:Mask R-CNN
(2017.03,何凯明(Meta))
- 亮点:Mask R-CNN 扩展 Faster R-CNN,在与原有边界框识别的分支并行添加一个用于预测对象掩码的分支。通过同时预测边界框和掩码,Mask R-CNN 能够更准确地识别和定位目标对象。
Faster R-CNN (2015.06, Microsoft)
- 论文:Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
(2015.06,Microsoft)
- 主要贡献点:
- 用于区域提议生成(region proposal generation)的网络架构 RPN(Anchors 概念、a pyramid of anchors,对应的损失函数和训练方法)。(见图 F1)
- RPN 和检测网络(例如 Fast R-CNN)共享特征(使用交替训练、近似联合训练等方法),减少冗余 CNN 计算。(见图 F2)
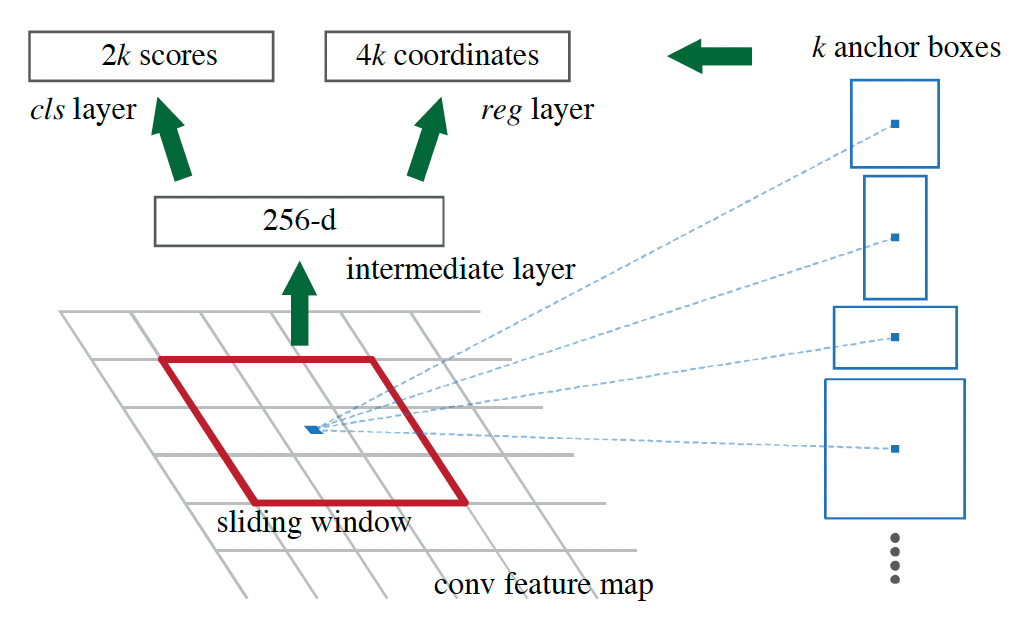 图 F1:Region Proposal Network (RPN) 中提出了 Anchor 方法(图片来源于 Faster R-CNN 论文)
图 F1:Region Proposal Network (RPN) 中提出了 Anchor 方法(图片来源于 Faster R-CNN 论文)
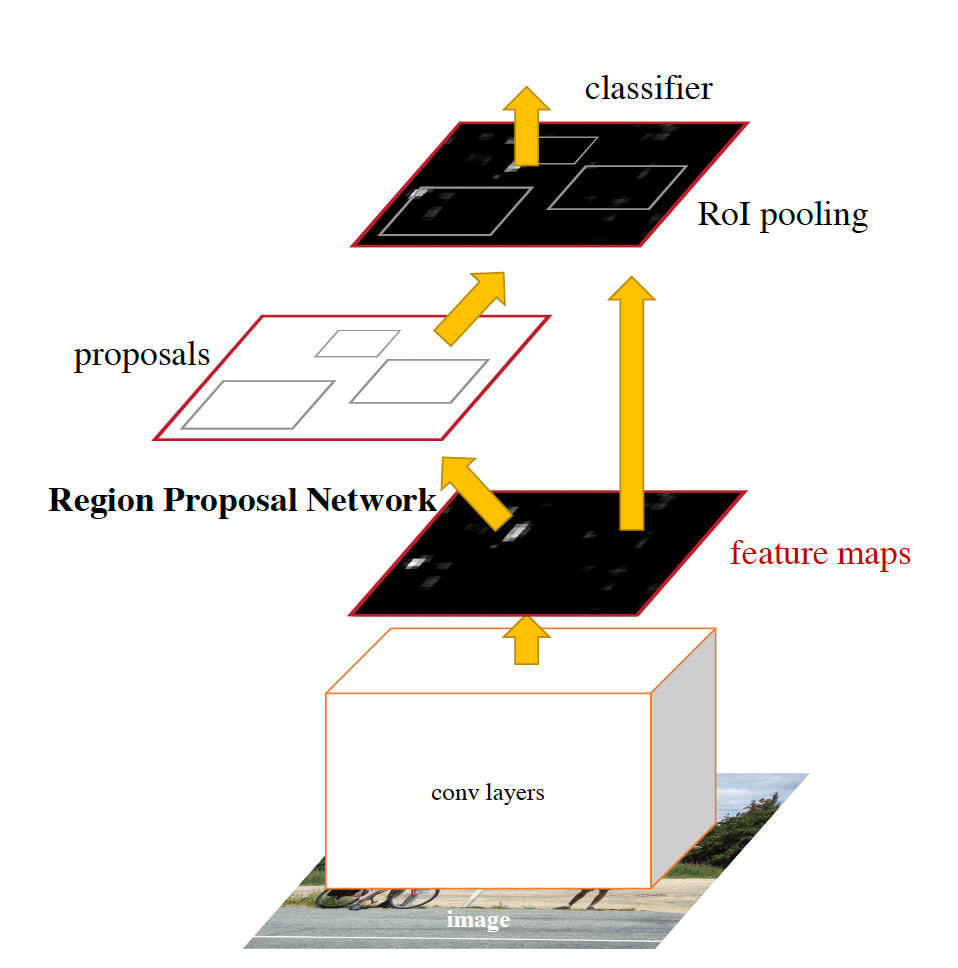 图 F2:Faster R-CNN 是一个单一的、统一的目标检测网络。RPN模块充当这个统一网络的“注意力”模块。(图片来源于 Faster R-CNN 论文)
图 F2:Faster R-CNN 是一个单一的、统一的目标检测网络。RPN模块充当这个统一网络的“注意力”模块。(图片来源于 Faster R-CNN 论文)
R-CNN (2013.11, UC Berkeley)
- 论文:Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation
(2013.11,UC Berkeley)
- 亮点:
- 将卷积神经网络(CNNs)应用到自下而上的区域提议中,以便定位和分割目标物体。
- 区域提议可以通过 selective search 等算法得到。
DETR 系列
目前霸榜的目标检测系列,榜单参考 Object Detection on COCO test-dev。
DETR (2020.05, Meta)
- 论文:End-to-End Object Detection with Transformers
(2020.05,Meta)
代码:facebookresearch/detr - 亮点
- 将目标检测看作集合预测问题
- object queries
- 去掉了 NMS、anchor 生成等包含先验知识的组件
- 总体架构为: CNN + Transformer + FFN
- a CNN backbone to extract a compact feature representation
- an encoder-decoder transformer
- a simple feed forward network (FFN) that makes the final detection prediction
- 将目标检测看作集合预测问题

DINO (DETR with Improved DeNoising Anchor Boxes) (2022.03,香港科技大学等)
和 2021.04 的论文《Emerging Properties in Self-Supervised Vision Transformers》重名了。
- 论文:DINO: DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
(2022.03,IDEA-Research/DINO)
代码:IDEA-Research/DINO

RT-DETR(2023.04,百度),实时检测
- 论文:DETRs Beat YOLOs on Real-time Object Detection
(2023.04,百度)
代码:lyuwenyu/RT-DETR - 另见 ultralytics 的实现

SAM(Segment Anything)系列
基于大模型的方法。
- 论文:Segment Anything
(2023.04,Meta)
代码:facebookresearch/segment-anything

损失函数
Focal Loss
- 论文:Focal Loss for Dense Object Detection
(2017.08,Meta)
IoU(评估指标和损失函数)
在计算对象检测评估指标 mAP(平均精度,mean Average Precision)时,计算 IoU(Intersection over Union)是非常关键的一步。因此,在训练过程中,常用 IoU (或者变体)作为损失函数的一部分。
原生 IoU(Intersection over Union)
- 论文:UnitBox: An Advanced Object Detection Network
(2016.08,UIUC、旷视)
- 亮点:IoU 衡量了两个边界框的交集区域与并集区域的比例。
GIoU(Generalized-IoU)
- 论文:Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression
(2019.02,斯坦福)
- 亮点:GIoU 解决了IoU 的不足(两个框不相交的情况)。
DIoU(Distance-IoU)和 CIoU(Complete-IoU)
- 论文:Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression
(2019.11,天津大学)
- 亮点:
- DIoU 通过两个中心点距离和对角线的比值来衡量框的距离关系,解决了 GIoU 中不相交和框包含两种情形下的问题。
- CIoU 论文和 DIoU 相同,CIoU损失在DIoU 的基础上,增加了纵横比的一致性要求。
其他重要论文
- Visualizing Data using t-SNE
(2008,L. Maaten, Geoffrey E. Hinton)
- Visualizing and Understanding Convolutional Networks
(2013.11,Matthew D. Zeiler, R. Fergus)
- DenseNet:Densely Connected Convolutional Networks
(2016.08,Cornell University;清华大学)
- SSD: Single-Shot MultiBox Detector
(2015.12,UNC Chapel Hill 等)
训练方法
Adam 等请参考其他文章。
发布于:2024-03-05 描述有误?我来纠错